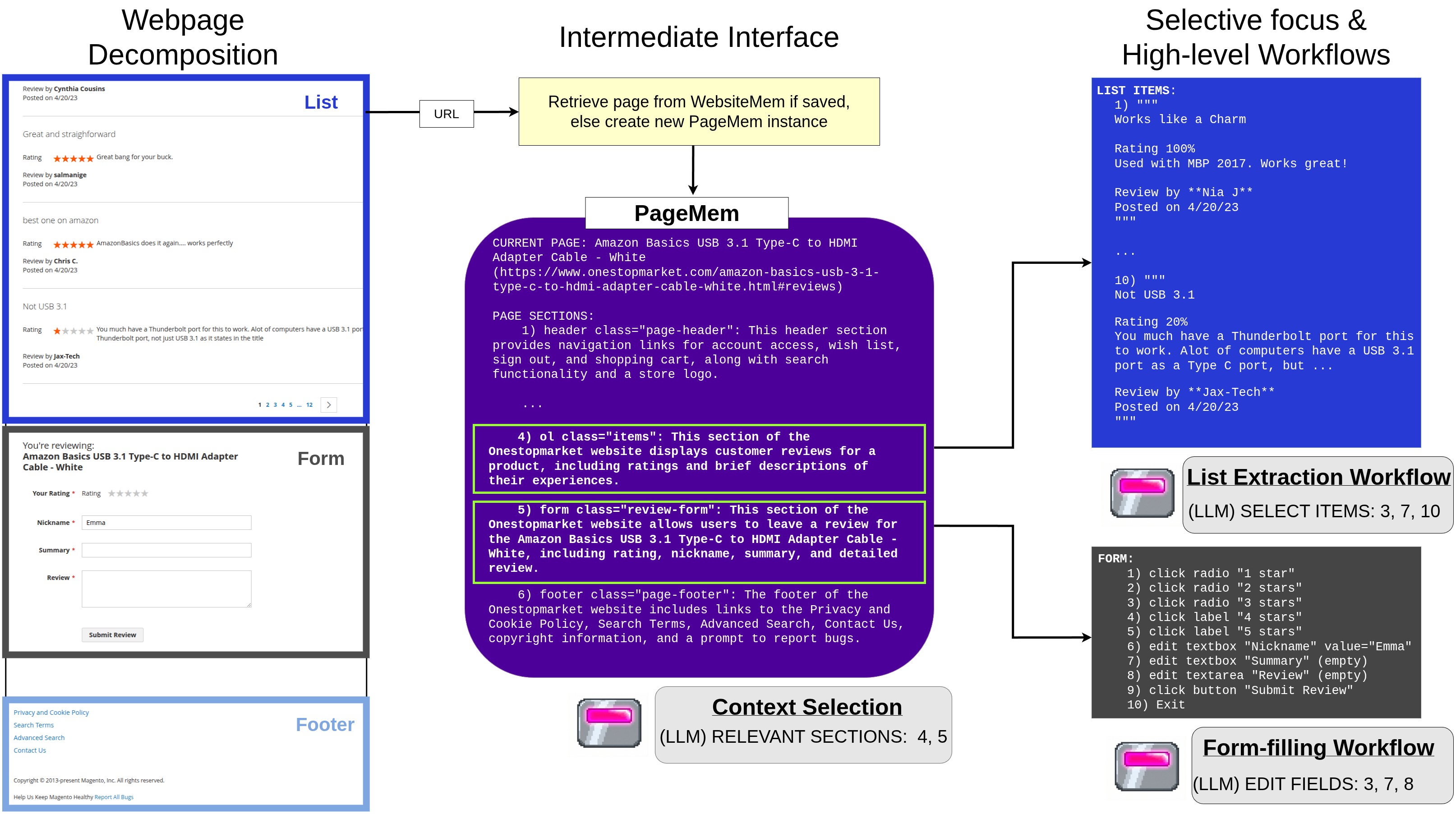
WebChallenger: A Reliable and Efficient Generalist Web Agent
WebChallenger is a web agent framework built around PageMem, a structured page representation that supports selective observation, persistent site memory, and compound action workflows.
Without fine-tuning, WebChallenger sets new open-model state-of-the-art across multiple web navigation benchmarks, showing scaffolding alone can drastically improve web agent performance.